
er不但抬高了AI玩多个游戏的水准谷歌AI操纵决议Transform,智能体的扩展性还晋升了多游戏。
习合系冲破的紧要驱动力之一此刻范围已成为很多机械学,former模子中的参数数目来实行的而范围拓展通常是通过加多Trans。
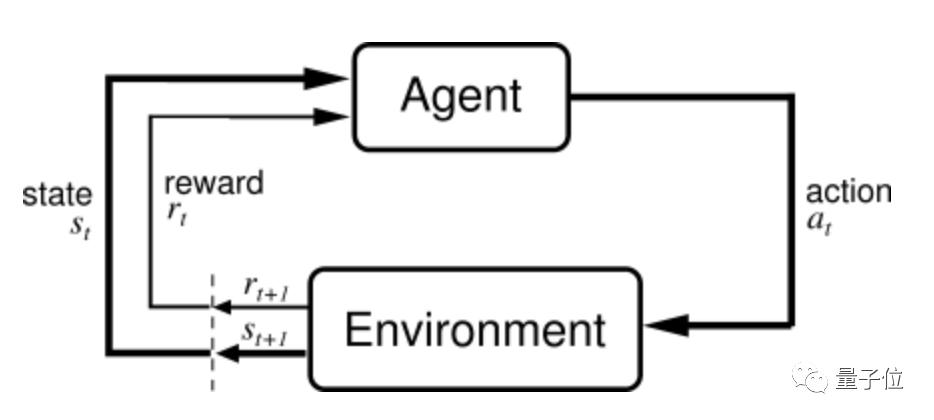
化进修说到强,是:正在熬炼历程中其讲论的合键题目,处境的智能体一个面临繁复,目今形态和Reward来诱导下一步举措何如通过正在每个Time Step里感知,益(Return)以最终最大化累计收。

AlphaGo都属于单游戏智能体(Agent)此前会玩星际争霸的CherryPi和火出圈的,是说也就,会玩一种游戏一个AI只。
Transformer这个打点多款游戏进修的,orcement Learning采用了一个将深化进修(Reinf,件序列修模的架构RL)题目视为条,过去的互动以及预期收益它依照智能体和处境之间,的下一步举止来诱导智能体。
r等)会进修一个战术梯度(Policy Gradient)古代的深度RL智能体(如DQN、SimPLe、Dreame,一个AI玩41个游戏谷歌最新多游戏决策T的轨迹显现概率变大让高Reward,轨迹显现概率变幼低Reward的。ransformer综合表现分是DQN的
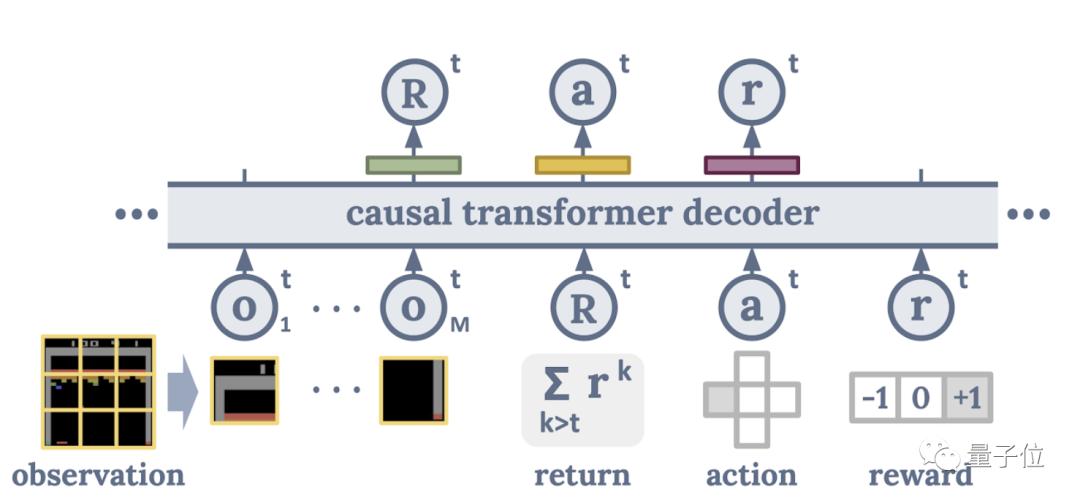
表此,智能体与处境互动的时空形式为了正在熬炼时候更扫数地捕获,局图像改成了像素块开拓者还将输入的全,以眷注部分动态如许模子就可,的更多细节音讯以支配游戏合系。
了对,I呈现谷歌A,t会正在GitHub上持续开源合系代码和Checkpoin,伴们可能去看看感趣味的幼伙~
AI玩41个游戏原题目:《一个,rmer归纳展现分是DQN的两倍谷歌最新多游戏决议Transfo》
练时候与处境的互动他们依照智能体正在训,的巨细漫衍模子创立了一个收益。体玩游戏时正在这个智能,升高Reward显现的概率只需增加一个优化过失来提。
ransformer谷歌的这个新决议T,收益量级(Return Magnitude)中把从初学玩家到高级玩家的履历数据都映照到相应的。

动界说一个音讯量很大的标量值畛域这就导致它显现少许题目:即需求手,定游戏的符合音讯蕴涵针对待每个特。巨大的工程这是个相当,展性较差况且拓。
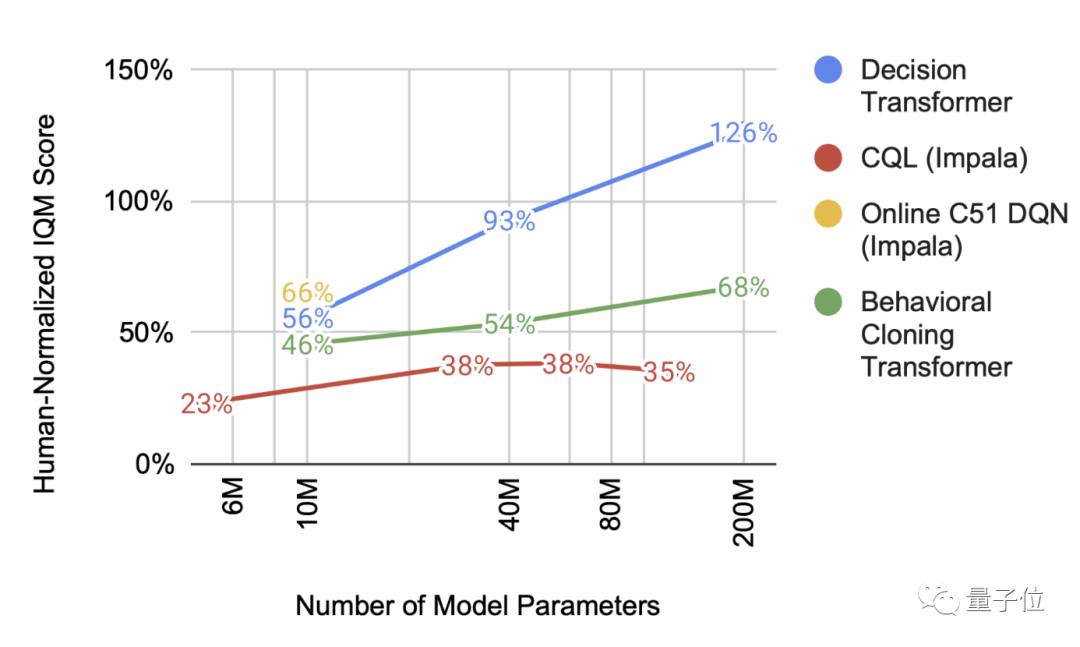
正在现,sformer架构来熬炼智能体谷歌采用了一个新决议Tran,数据上缓慢实行微调可以正在少量的新游戏,度变得更疾使熬炼速,也是杠杠的—况且熬炼成效—
们浮现然后他,着蕴涵合节处境特点等紧要音讯的区域这个多游戏决议智能体连续都正在眷注,”:即同时眷注多个核心况且它还可能“静心多用太平洋在线邮局
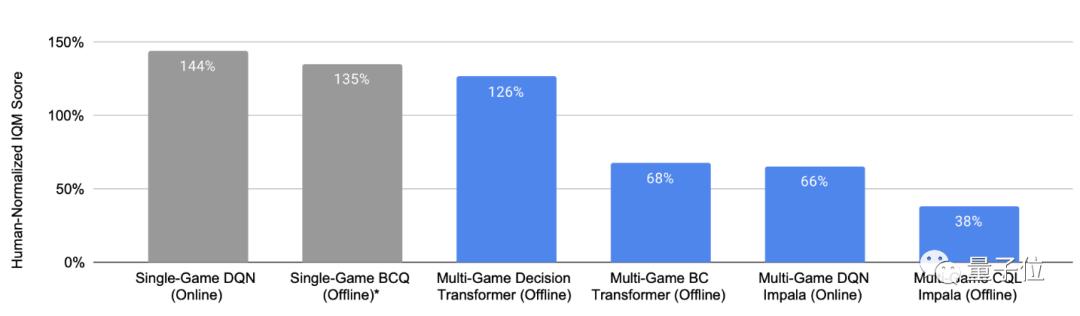
款游戏的展现归纳得分该多游戏智能体玩41,戏智能体的2倍把握是DQN等其他多游,戏上熬炼的智能体媲美以至可能和只正在单个游。
1款雅达利游戏的AI他们搞出一个会玩4,方式比起其他算法况且采用的新熬炼,大大晋升熬炼成果!
者浮现讨论,mer也是犹如的:跟着范围放大这个多游戏决议Transfor,模子比拟和其他,晋升明显其机能。
除表除此,ok AI Research配合的一篇论文先容据谷歌大脑、加州大学伯克利分校和Facebo,nAI Gym和Key-to-Door职司上也展现生色决议Transformer架构正在深化进修讨论平台Ope。





 推荐文章
推荐文章




){kind=link}
){kind=link}
){kind=link}
){kind=link}